AI 产品 PRD
费曼学习工具 - 深度学习引擎
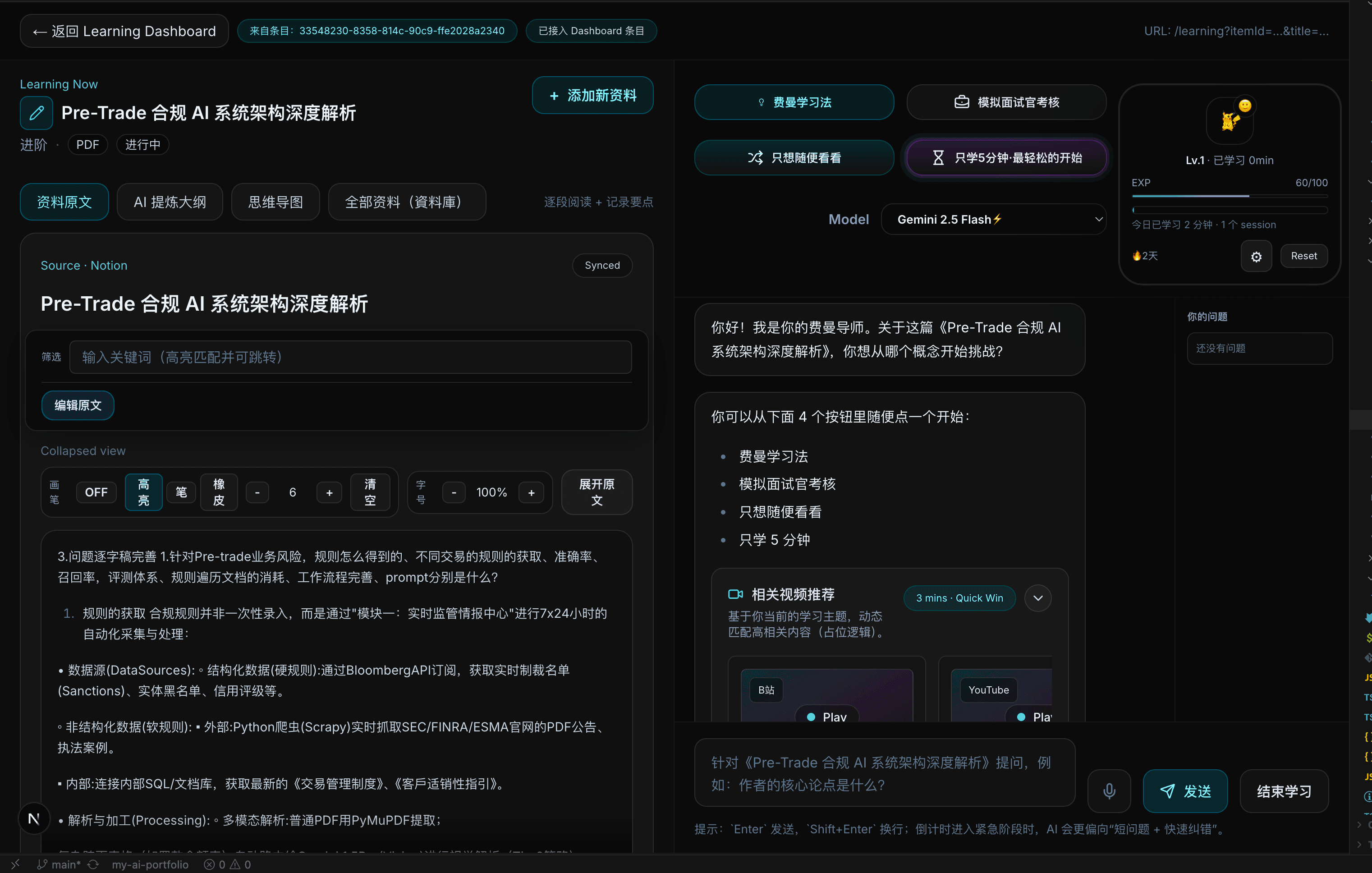
AI 驱动的主动学习系统:材料导入与结构化拆解、费曼 5 轮复述、AI 面试官压力测试、艾宾浩斯复习与 ADHD 友好启动设计。学习数据写回用户 Notion,而非锁在聊天窗口。
产品总览
一、产品概述
业务背景
学习复杂材料时常见「看过即忘」,传统笔记难检验是否真懂,面试前又缺乏低成本演练环境。
产品目标
做一款 NotebookLM 风格双栏产品:左栏降低认知负荷,右栏用费曼对话 + AI 考官验证理解,并把掌握度写回 Notion。
AI 能力边界(AI 产品 PRD 必填)
- 能做:Gemini 解析材料生成大纲/大白话/Mermaid;费曼 5 轮引导复述;DeepSeek 模拟面试与评分;掌握度与复习队列写回 Notion。
- 不能做:不替代正式学位课程考核;面试模拟基于已导入材料,非全行业通用题库。
- ADHD 设计:只奖励不惩罚,中断不扣分;「只学 5 分钟」降低启动门槛。
- 双模型分工:解析/费曼用 Gemini Flash;面试/评分用 DeepSeek,非单一模型包办。
二、功能定义
功能矩阵
| 模块 | 用户价值 | 要点 |
|---|---|---|
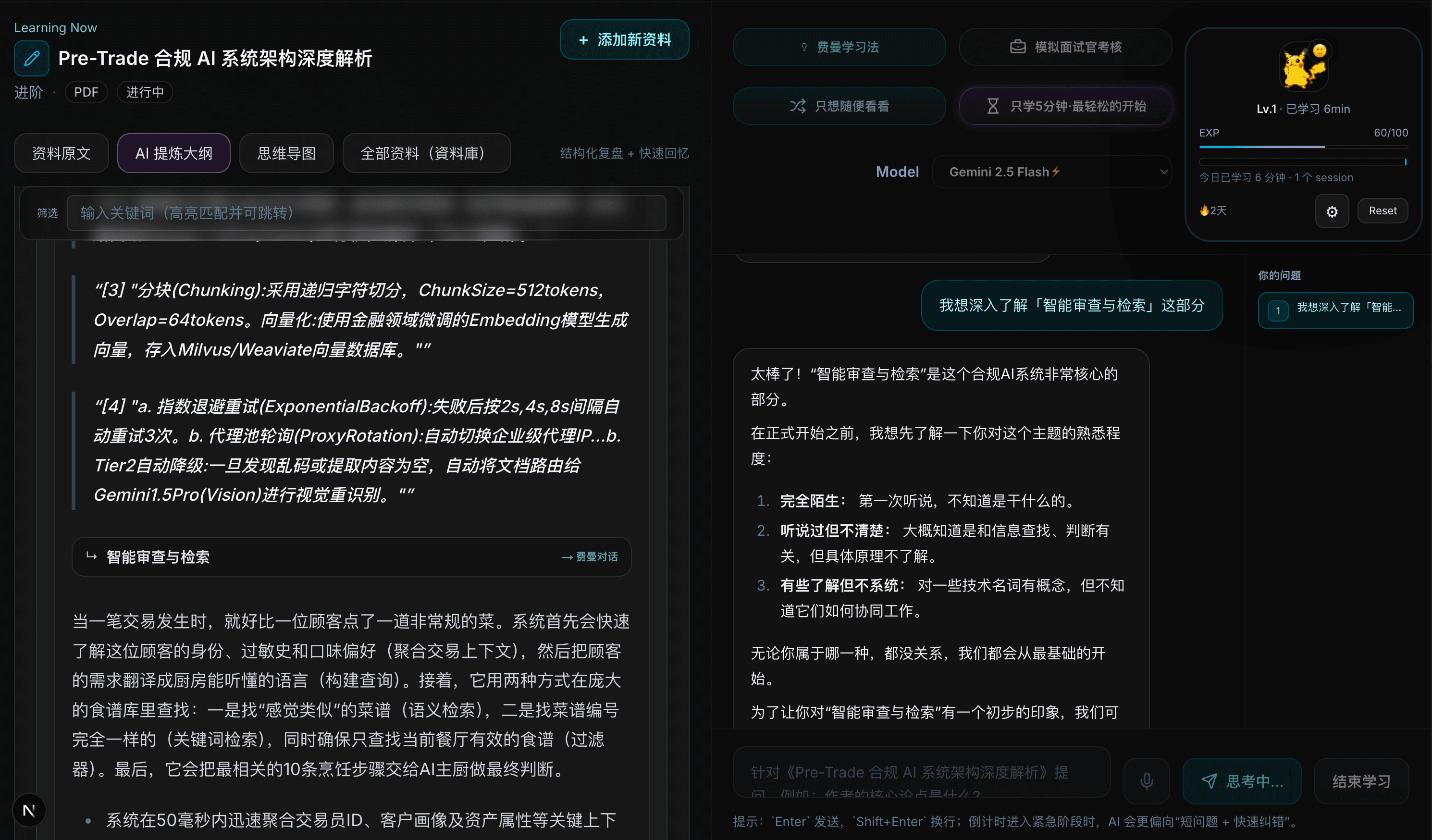
| 学 + 考双引擎 | 理解 vs 表达 | 费曼环节解决「是否理解」,AI 面试官解决「压力下能否表达」。两者串联但不混用,避免用聊天代替测评。答错自动入复习队列,把产品从内容消费工具升级为能力训练工具。 |
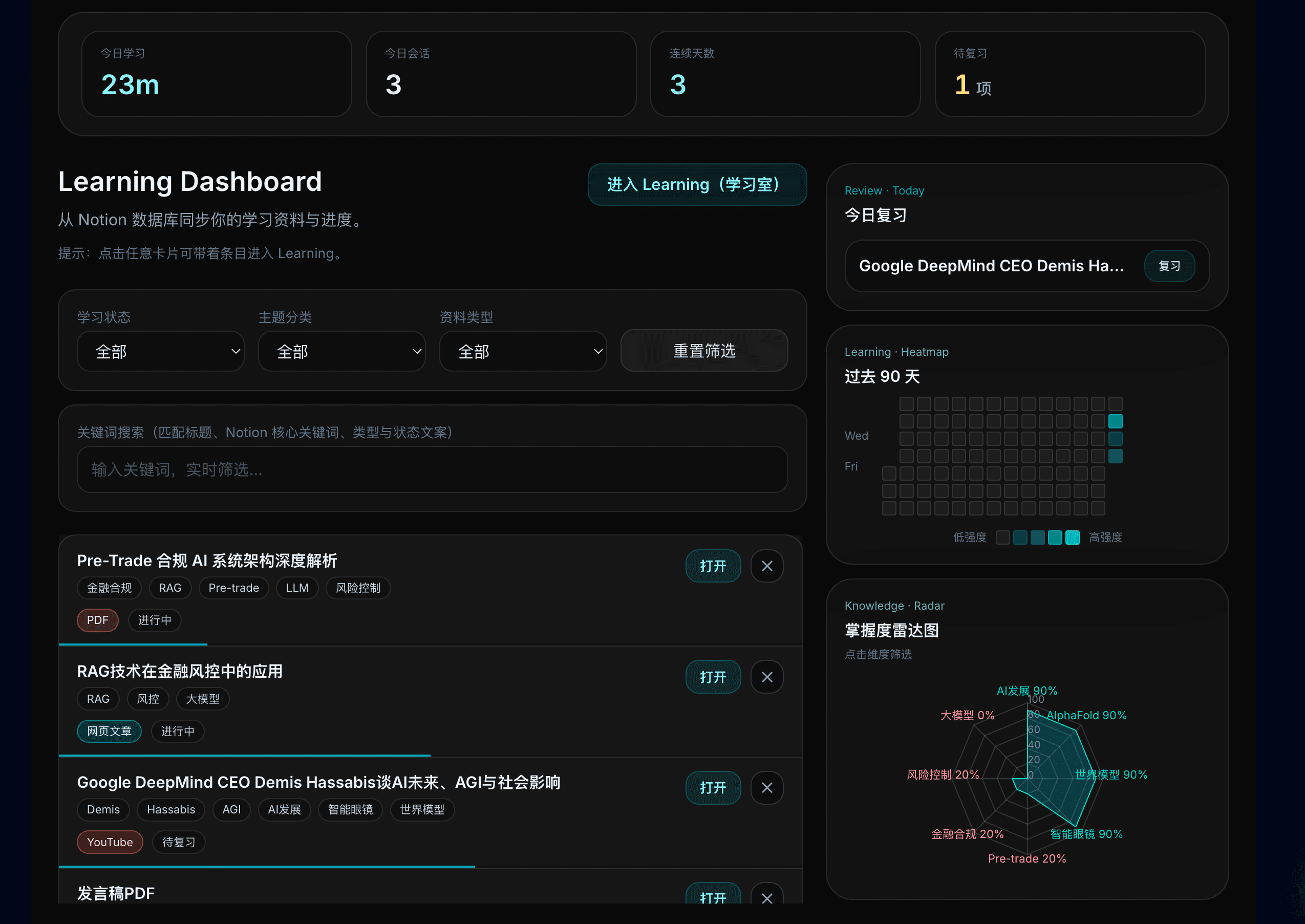
| Notion 沉淀 | 数据归属用户 | 学习记录、费曼笔记与复习计划写回用户 Notion,尊重已有知识管理工作流。PM 视角这是降低迁移成本、提高留存的关键——数据在用户侧,产品做增强层而非孤岛。 |
| ADHD 友好 | 降低启动成本 | 针对启动困难设计短任务默认、正计时与无惩罚激励,减少「还没开始就放弃」。通过降低单次承诺时长,提高周活跃与材料完成率,属于行为设计而不仅是功能堆叠。 |
用户交互流程
材料导入 ➔ 结构化拆解 ➔ 费曼讲解 ➔ AI 面试考核 ➔ 复习队列 ➔ 掌握度画像
- 设计材料导入、概念拆解、追问梯度与复习队列;加入 ADHD 友好的短时段启动与正向激励。
- 形成学—讲—考—复习闭环,用户可在压力场景前发现盲点,学习数据留在自己的知识库而非锁死在聊天窗口。
边界与容错
- 费曼与面试模式串联但不混用 UI,避免用聊天代替测评。
- 答错进入复习队列,由间隔重复算法生成待练列表。
- API 密钥仅存服务端 Route,前端不暴露 Key。
三、效果展示
量化指标与验收
| 指标 | 说明 |
|---|---|
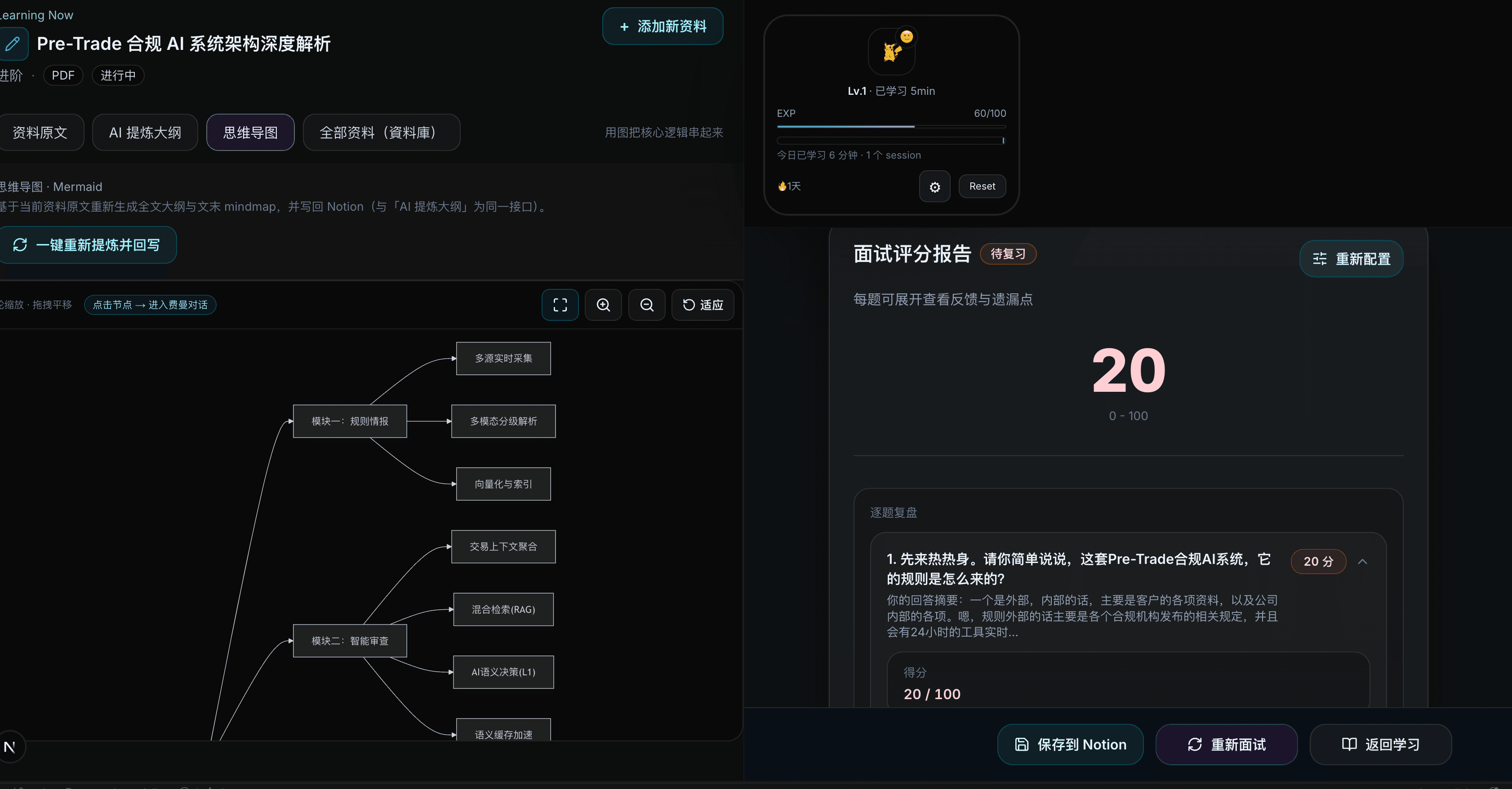
| 掌握度 | 0–100 分,按对话质量评估 |
| 复习间隔 | 1 / 3 / 7 / 14 / 30 天艾宾浩斯曲线 |
| 热力图 | 90 天学习活跃度 GitHub 风格 |
| 费曼框架 | 固定 5 轮追问梯度 |
数据要求(AI 产品 PRD 必填)
- 输入:PDF / 视频文稿 / 粘贴文本;用户 Notion 工作区凭据。
- 输出:会话记录、掌握度、费曼笔记、复习计划写回 Notion API。
- 结构化:面试评分报告(得分、盲点、建议);Mermaid 思维导图节点可点击进费曼。
- 非训练:Prompt 驱动双模型,无自有标注训练集。
Bad Case 定义与处理(AI 产品 PRD 必填)
| Bad Case | 处理策略 |
|---|---|
| Gemini 解析失败 | 提示重试或缩短材料 |
| 面试回答模糊 | 追问具体化,非直接给答案 |
| Notion 写入失败 | 会话仍可在前端继续,稍后重试同步 |
| 用户中断学习 | 正计时无惩罚,欢迎回来提示 |
四、技术选择
模型选择
| 场景 | 模型 |
|---|---|
| 解析 / 费曼 | Gemini 2.5 Flash |
| 面试 / 评分 | DeepSeek Chat |
| 前端 | Next.js 15 + Vercel AI SDK 流式 |
数据处理
基于 Next.js App Router:左侧材料区支持上传 PDF/粘贴文本,解析上传材料生成总结文档解析与 Mermaid 概念图,右侧费曼与 AI 面试官分别调用 Gemini、DeepSeek 流式对话,追问按掌握度分级。学习状态、笔记与复习队列经 Notion API 写回用户工作区,服务端路由保护密钥;复习调度按间隔重复生成待练列表,正计时与轻量任务降低启动门槛。
系统架构
正在渲染图表...
五、学到的经验
- Prompt 即产品:5 轮费曼框架需反复迭代才稳定。
- 双模型分工平衡成本与效果(Flash 高频 + DeepSeek 推理)。
- 数据在 Notion 侧是降低迁移成本、提高留存的关键。
六、将来迭代计划
| 方向 | 内容 |
|---|---|
| 材料 | 更多视频源解析优化 |
| 社交 | 学习小组/分享卡片 |
| 宠物 | PokeFocusPet 更多激励形态 |