AI 产品 PRD
AI News Radar · 每日 AI 资讯
Web 端深度阅读与飞书即时触达:精选经 Engine A(ai-news-update)fetch-news 写入 Notion;日报 Tab 直连 AI HOT 官方归档;飞书菜单由 job_engine 门卫最高优先级转发至本仓库 Node 卡片引擎。
产品总览

一、产品概述
业务背景
AI PM 需每日掌握模型与产品动态,信息源分散在网站、社群与日报产品,通过飞书实现「点菜单即看资讯」的方式,与求职工具共用同一机器人。
产品目标
建设 Web 三视图 + 飞书卡片双端体验,精选可沉淀、日报要权威、推送要不打扰其他能力。
AI 能力边界(AI 产品 PRD 必填)
- 能做:Engine A 采集 HN/Polymarket/YouTube 经 fetch-news 入库 Notion;拉取 AI HOT 日报/分类渲染飞书卡片;Web 端标星写回 Notion。
- 不能做:不自行爬取非 Engine A / AI HOT 源;不生成原创深度研报;飞书侧不负责求职采集/背调(由 job_engine 路由隔离)。
- 日报体验:AI 日报 Tab 读官方 API 归档正文,不经 Notion 二次拼装,保证与 AI HOT 产品一致。
- 非训练:摘要与卡片文案为 API 数据 + 模板/路由逻辑,无离线训练流水线。
二、功能定义
功能矩阵
| 模块 | 用户价值 | 算法 / 逻辑要点 |
|---|---|---|
| 精选入库 | 高信噪比沉淀 | npm run fetch-news → Engine A /api/news;北京时区今/昨;URL 去重写 Notion |
| 三视图 Web | 分层阅读 | 精选 / 全部(Notion)+ AI 日报(API 最近 30 期 + 按日正文) |
| 首页预览 | 轻量触达 | AINewsWidget:Notion 全量倒序最多 20 条,链至 /ai-news |
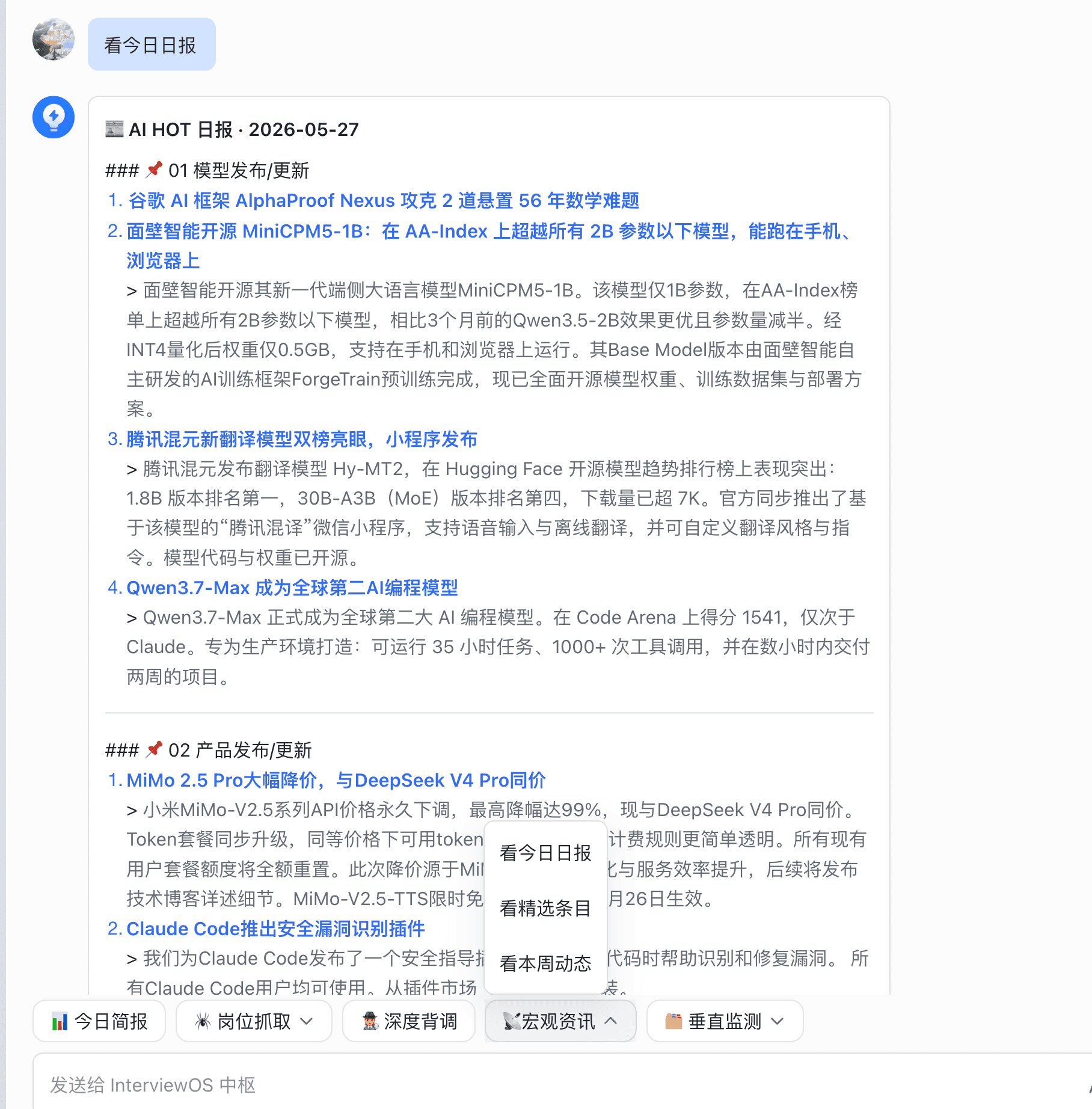
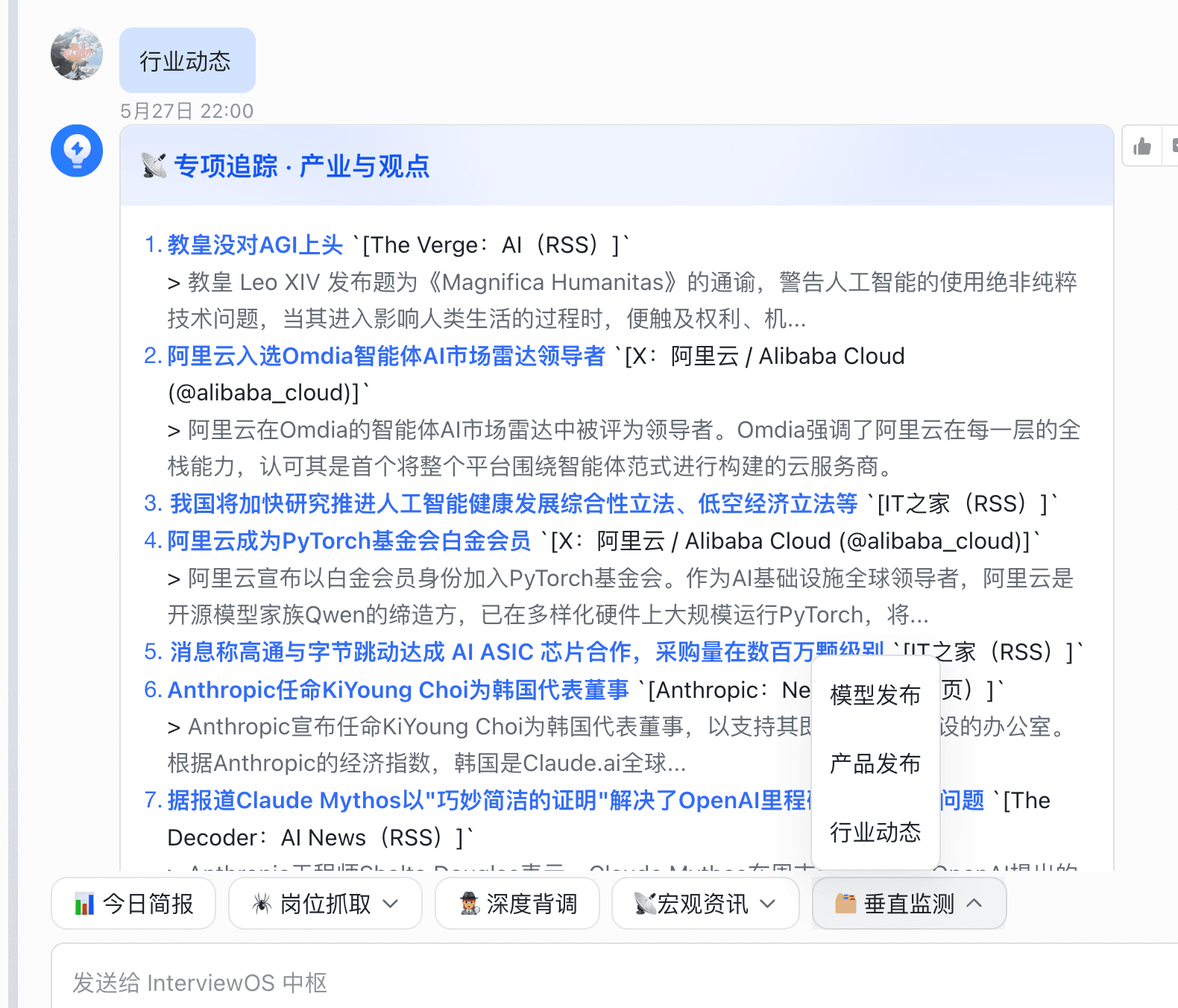
| 飞书卡片 | 移动秒读 | 飞书点 6 条底部菜单 → Python 门卫识别后转本机 Node → 拉 AI HOT 生成卡片 → 发回当前聊天 |
| 标星 | 个人清单 | PATCH /api/ai-news/star 同步 Notion |
用户交互流程
- 定义六条飞书菜单与对应内容策略,网关层优先识别资讯指令;精选走定时入库,日报直连官方归档,卡片由独立渲染服务生成。
- 用户可在飞书秒级获取日报/精选/分类动态,网站端支持深度阅读与标星,资讯与求职指令互不串线。
边界与容错
- 菜单文案须与飞书后台一字不差,否则 router 无法命中。
- 资讯指令必须在 route_intent 之前拦截,避免「看看精选」等误触发背调。
- 精选入库依赖手动或自建调度(无 Vercel Cron 时本地 fetch-news)。
- Node 卡片引擎未启动时,飞书菜单不可用,Web 端仍可读 Notion。
三、效果展示
量化指标与验收
| 指标 | 验收方式 | 说明 |
|---|---|---|
| 飞书菜单 | 6 条暗号均可出卡 | 看今日日报、看精选、看本周、模型/产品/行业 |
| 精选入库 | 今昨 + URL 去重 | lib/cron-fetch-news.ts |
| 首页预览 | 最多 20 条 | sortNewsNewestFirst,无时间 Tab 筛选 |
| 日报 | take=30 归档 | /api/ai-news/dailies + /daily/{date} |
| 路由隔离 | 资讯不误触求职 | 资讯菜单先处理并 return,不进入求职爬虫/背调 |
数据要求(AI 产品 PRD 必填)
- 输入:Engine A JSON(Title/Source/Author/URL/OriginalText/Date);AI HOT API(日报/飞书菜单);Notion 资讯库字段。
- 精选策略:Engine A days=1 + 北京时区今/昨过滤 + URL 主键去重。
- 输出:Notion 页面记录;飞书 interactive 卡片 JSON(feishu-card-builder)。
- 非训练:Engine A 依赖 DeepSeek/Gemini 在线翻译;飞书/日报依赖 AI HOT editorial 策略。
Bad Case 定义与处理(AI 产品 PRD 必填)
| Bad Case | 预期表现 | 处理策略 |
|---|---|---|
| Engine A API 失败 | Web 可读 Notion 缓存 | Notion 已沉淀条目仍展示;重试 fetch-news |
| AI HOT API 失败 | 飞书卡片/日报降级 | 飞书返回错误提示;日报 Tab 展示错误态 |
| Node :3001 未启动 | 飞书菜单不可用 | README 要求双引擎联调;日志 node_api.log |
| 菜单文案不匹配 | 无卡片 | 严格对齐飞书后台与 aihot-router 暗号表 |
| 误触背调 | 不启动爬虫 | 网关层资讯优先,不进入 route_intent |
| 重复条目 | 不重复入库 | fetch-news URL 去重 |
四、技术选择
模型选择
| 场景 | 技术 | 说明 |
|---|---|---|
| 内容源 · 精选 | ai-news-update Engine A | HN / Polymarket / YouTube + DeepSeek 翻译 |
| 内容源 · 日报/飞书 | AI HOT 公开 REST | 日报归档 / 分类 / 飞书菜单 |
| 精选入库 | Node 脚本 | lib/cron-fetch-news.ts → Engine A /api/news |
| Web | Next.js App Router | /ai-news、AINewsWidget、API Routes |
| 飞书卡片 | Express + feishu-local-api | tools/aihot-router、feishu-card-builder |
| 持久化 | Notion API | NOTION_AI_NEWS_DB_ID |
数据处理
- 采集:Engine A API → fetch-news → Notion(精选);日报不经 Notion。
- Web 读:fetchAINewsRadarFromNotion SSR;日报走 aihot-daily-api 封装。
- 飞书:点菜单 → Python 门卫识别资讯指令 → Node :3001 拉 AI HOT 并生成卡片 → 门卫把卡片发回当前聊天(不触发求职爬虫/背调)。
- 标星:PATCH /api/ai-news/star 更新 Notion 属性。
系统架构
路径一:在网站 /ai-news 阅读
正在渲染图表...
路径二:在飞书聊天里收资讯卡片
正在渲染图表...
五、学到的经验
- 三视图分层比单列表更能控制认知负荷:精选判断价值、全部检索、日报对齐官方。
- 与 Job Engine 共机器人时,网关优先级是产品级需求,不是实现细节。
- 飞书负责触达、网站负责深度阅读,职责清晰可降低交互设计复杂度。
六、将来迭代计划
| 方向 | 内容 |
|---|---|
| 自动化 | 自建 CI/Cron 定时 fetch-news |
| 体验 | 飞书卡片版式对比(如紧凑列表 vs 杂志导读)、分类订阅 |
| 数据 | 个人高价值清单导出与分享 |